Institute for Surface Technology GmbH
Contact at the AI Innovation Center
Andreas Frommknecht
Damage evaluation of rockfalls with machine learning
Initial situation
The underbody of cars must be protected against damage. This can be caused, for example, by small foreign objects such as gravel that are thrown up when driving and must then be detected. For this purpose, sharp-edged steel gravel is shot onto samples in laboratory tests using compressed air and the damage pattern is evaluated using comparative images or by manual counting. Problems arise because the assessment is to a certain extent subjective and also very time-consuming. Digital automatic analysis of the damage pattern allows more and more precise characteristic values to be recorded with greater consistency and objectivity.
Solution idea
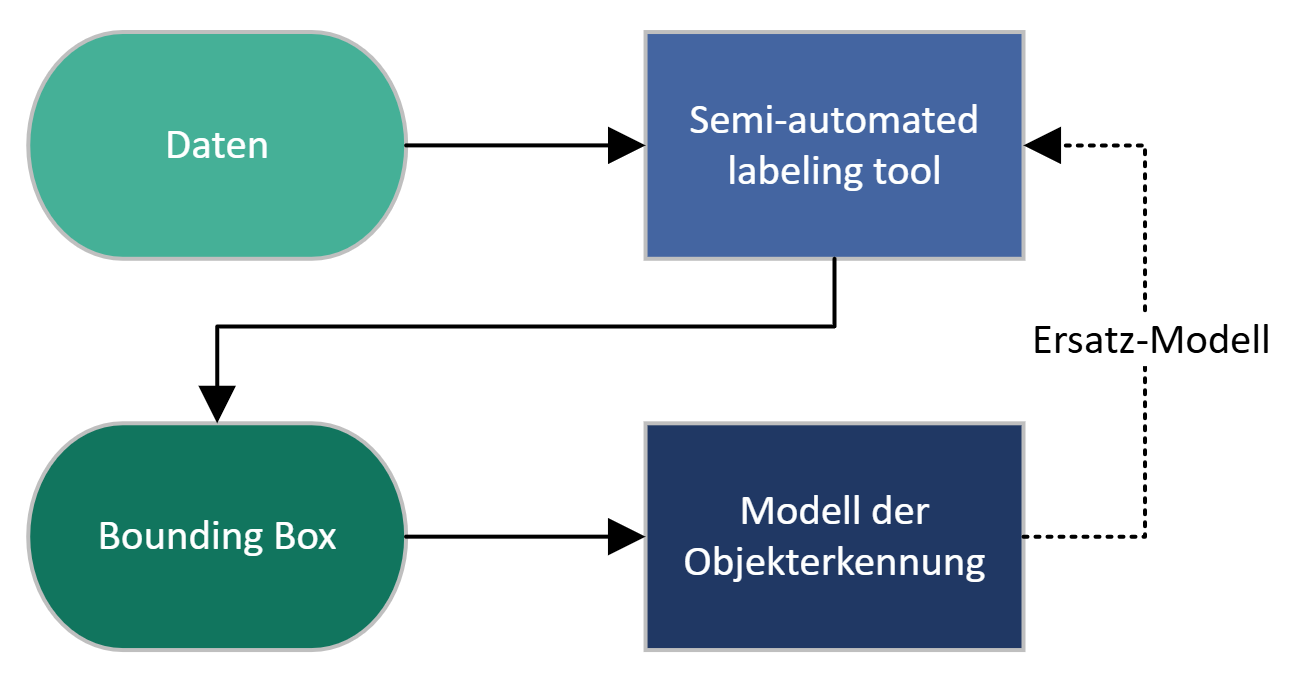
This Exploring Project aimed to improve the robustness and flexibility of the current AI-based detection system for stone chip damage from the previous Quick Check, while also testing new training methods. With the increased complexity of the data, manual labeling efforts have also increased significantly. To facilitate this, a semi-automated labeling tool was developed. This tool generates a large labeled data set that can be used to train more accurate models.
Benefit
- Improved evaluation and documentation across several stages of a laboratory test
- Quick and easy quantification/counting of damage - In order to generate large amounts of training data quickly and reliably, labeling is supported and simplified by the development of "semi-automated labeling"
- Different damage mechanisms in practice can be analyzed in more detail and compared between different areas of the vehicle
- Recognizing the damage mechanisms allows the development of new and more durable painting systems and strategies
Implementation of the AI application
A basic model called "Segment Anything" creates a versatile segmentation model that can identify objects in images. With this model, the new "semi-automated labeling tool" can draw bounding boxes around the defective areas. Although the dataset is limited and the features are smaller, the performance of the tested object recognition model is actually not yet as accurate as the models from the Quick Check. Nevertheless, it has shown promising results and is expected to be further improved with a larger dataset.