»The project has demonstrated the enormous potential that can be leveraged through generative AI and LLMs. However, further steps need to be taken during implementation in order to process the complex and diverse data. With the right expertise, success is within reach.«
Jens Esser, Head of IT Enayati
Enayati Surface Technology GmbH
Contact at the AI Innovation Center
Andreas Frommknecht
EnayaKI (Enayati Calculation Interface)
Initial situation
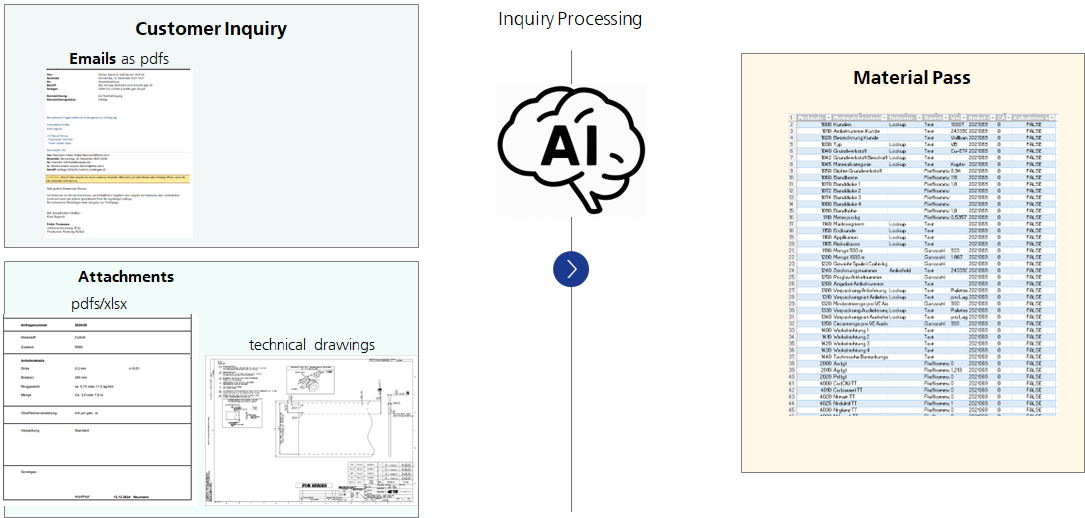
Customer inquiries are usually received in unstructured form as drawings, text and additional information by e-mail. The required materials and their quantities for order execution are currently determined manually from these inquiries. Staff then fill out the request evaluation sheet with additional information and the data determined.
However, calculating the material consumption in particular is very time-consuming and ties up a lot of capacity, as various pieces of information have to be checked manually, such as dimensions in the drawings, information in the continuous text and sometimes complex geometries. This work step considerably extends the throughput time for preparing quotations. There is therefore potential for optimization in order to reduce the process time using artificial intelligence.
Solution idea
Our solution approach is based on the AI-supported extraction of the relevant information from the customer inquiry in order to determine the material consumption for the coating.
Two complementary approaches are being pursued:
- Image analysis of the drawings to determine the relevant dimensions
- Text analysis to extract relevant information from the e-mail itself and the attachments, some of which contain additional information and drawing texts
Once this information has been extracted, it can be automatically transferred to the request evaluation sheet.
Benefit
- Fast and precise recording of cost-relevant metadata (e.g. article number, material, width, thickness)
- Compliance with Enayati's data requirements; automatic storage in the required formats (e.g. CSV/ERP import templates)
- Shorter quotation processing times, which enables a faster response time and therefore a competitive advantage
- Mitigating skills shortages, absenteeism and rising labor costs through automation
- Improved data transparency and analysis for continuous process optimization
These benefits scale proportionally with the number of customer inquiries.
A multimodal LLM was also tested to extract the information based solely on drawings. However, the evaluated multimodal model is currently less accurate than rule-based algorithms. However, it is expected that it can be improved through further optimization and fine-tuning.
Implementation of the AI application
Optical Character Recognition (OCR) is a technology that can identify and digitize text from images or scanned documents. The extracted text information is post-processed using either rule-based algorithms or Large Language Models (LLMs). Rule-based algorithms recognize the relevant information in the vicinity of the defined keywords. They are flexible and accurate if the relevant information is located in the expected positions. LLMs, on the other hand, search for information with text prompts and are used for both drawings and text-based input. LLMs can process new document types effectively, and their integration into the rule-based pipeline further optimizes the workflow.