»Das Projekt hat die enormen Potenziale aufgezeigt, die sich durch generative KI und LLMs heben lassen. Im Rahmen der Umsetzung sind jedoch weitere Schritte notwendig, um die komplexen und vielfältigen Daten zu verarbeiten. Mit der richtigen Expertise ist der Erfolg greifbar.«
Jens Esser, Leiter IT Enayati
Enayati Oberflächentechnik GmbH
Contact at the AI Innovation Center
Andreas Frommknecht
EnayaKI (Enayati Calculation Interface)
Initial situation
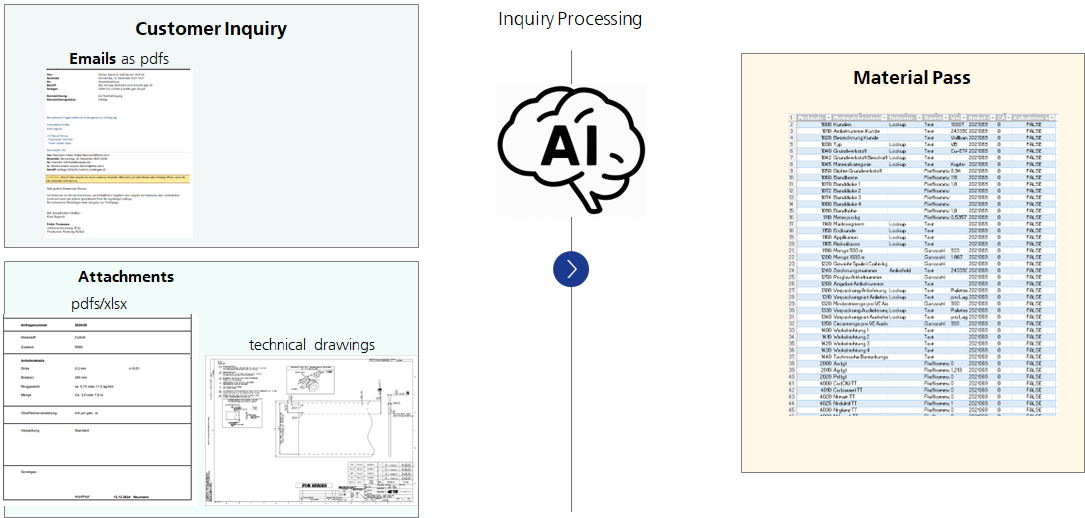
Kundenanfragen gehen in der Regel in unstrukturierter Form als Zeichnungen, Text und zusätzliche Informationen per E-Mail ein. Die benötigten Materialien und deren Mengen für die Auftragsausführung werden aus diesen Anfragen derzeit manuell ermittelt. Anschließend füllt das Personal das Anfragebewertungsblatt mit zusätzlichen Informationen und ermittelten Daten aus.
Insbesondere die Berechnung des Materialverbrauchs ist jedoch sehr zeitaufwendig und bindet viel Kapazität, da verschiedene Informationen manuell überprüft werden müssen, wie z. B. Maße in den Zeichnungen, Informationen im Fließtext und manchmal komplexe Geometrien. Dieser Arbeitsschritt verlängert die Durchlaufzeit für die Angebotserstellung erheblich. Es besteht entsprechend Optimierungspotenzial, um die Prozesszeit durch Künstliche Intelligenz zu reduzieren.
Solution idea
Unser Lösungsansatz basiert auf der KI-gestützten Extraktion der relevanten Informationen aus der Kundenanfrage, um den Materialverbrauch für die Beschichtung zu ermitteln.
Dabei werden zwei sich ergänzende Ansätze verfolgt:
- Bildanalyse der Zeichnungen zur Ermittlung der relevanten Maße
- Textanalyse zur Extraktion relevanter Informationen aus der E-Mail selbst und den Anhängen, die teilweise zusätzliche Informationen und Zeichnungstexte erhalten
Nach der Extraktion dieser Informationen können diese automatisch in das Anfragebewertungsblatt übertragen werden.
Benefit
- Schnelle und präzise Erfassung kostenrelevanter Metadaten (bspw. Artikelnummer, Material, Breite, Dicke)
- Einhaltung der Datenanforderungen von Enayati; automatische Speicherung in den erforderlichen Formaten (z. B. CSV/ERP-Importvorlagen)
- Kürzere Angebotsbearbeitungszeiten, was eine schnellere Reaktionszeit und somit einen Wettbewerbsvorteil ermöglicht
- Milderung von Fachkräftemangel, Fehlzeiten und steigenden Arbeitskosten durch Automatisierung
- Verbesserte Datentransparenz und -analyse für eine kontinuierliche Prozessoptimierung
Diese Vorteile skalieren proportional mit der Anzahl der Kundenanfragen.
Ein multimodales LLM wurde ebenfalls getestet, um die Informationen ausschließlich anhand von Zeichnungen zu extrahieren. Das evaluierte multimodale Modell arbeitet derzeit aber weniger genau als regelbasierte Algorithmen. Es wird jedoch erwartet, dass es durch weitere Optimierungen und Feinabstimmungen verbessert werden kann.
Implementation of the AI application
Optical Character Recognition (OCR) ist eine Technologie, die Text aus Bildern oder gescannten Dokumenten identifiziert und digitalisieren kann. Die extrahierten Textinformationen werden entweder durch regelbasierte Algorithmen oder Large Language Models (LLMs) nachbearbeitet. Regelbasierte Algorithmen erkennen die relevanten Informationen in der Nähe der definierten Schlüsselwörter. Sie sind flexibel und genau, wenn die relevanten Informationen sich an den erwarteten Positionen befinden. LLM dagegen suchen nach Informationen mit Text-Prompts und werden sowohl für Zeichnungen als auch für textbasierte Eingaben verwendet. LLMs können neue Dokumenttypen effektiv verarbeiten, und ihre Integration in die regelbasierte Pipeline optimiert den Workflow zusätzlich.