Robert Bosch Manufacturing Solutions GmbH
Contact at the AI Innovation Center
Werner Kraus
Peg-Men: Flexible assembly under disturbance variables
Initial situation
The process of inserting and removing sensitive valve needles into holders for subsequent coating is a time-consuming and repetitive task that cannot currently be performed using conventional automation technology (particularly robot programming). This is mainly due to the tolerances and process inaccuracies that need to be taken into account, as well as the lack of flexibility of robot-based automation solutions. For this reason, the programming of industrial robots is currently not economically feasible.
Solution idea
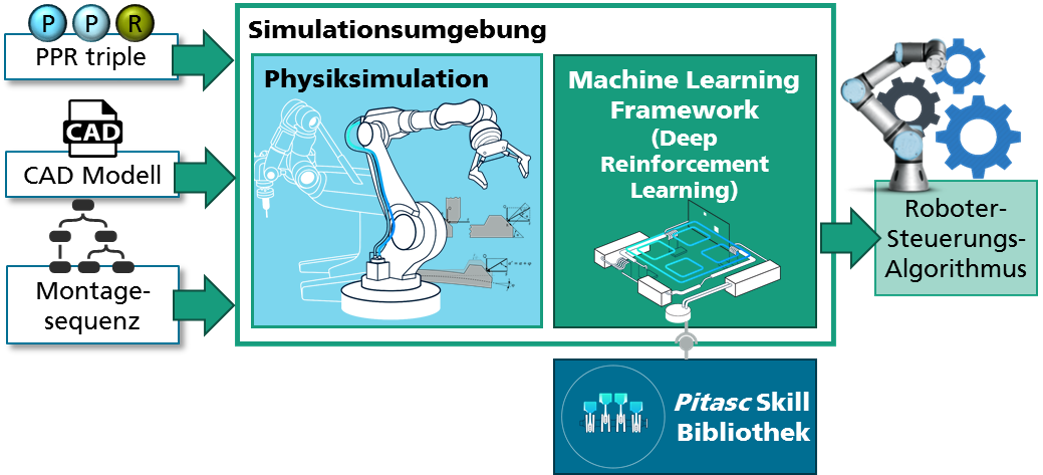
The underlying process is comparable to a classic peg-in-hole process, which has already been successfully and flexibly implemented at the Center for Cognitive Robotics. The training is carried out using deep reinforcement learning in a powerful physics simulation with variation of the process inaccuracies. The robot captures its environment during training in the simulation by integrating the sensors used in the real robot system into the digital twin of the simulation. By varying the process characteristics, the robot is trained to perform the joining process robustly.
Benefit
For the partners involved, the practical application of control algorithms generated from the simulation is a first important component of the medium and long-term goal of cognitive assembly cells. The conclusions drawn from the real processes flow directly into the technological improvement of the concept of self-learning, cyber-physical systems.
The findings show the potential of combining machine learning and simulation techniques with the aim of automating currently non-automatable, repetitive tasks in order to relieve the burden on humans.
Implementation of the AI application
To train the robot control algorithms, the underlying assembly process is mapped in the system's digital twin. For this purpose, both the robot with its gripper and the components used are digitally modeled. For the actual training, the learning algorithm varies the parameters of the robot program depending on the situation and receives a reward or punishment depending on whether it has come closer to its goal or not. In order to expand the possible solution space
and speed up training, the pitasc skill programming is used for the robot.