DER TRENDBEOBACHTER Mathias Haas
Kontakt am KI-Fortschrittszentrum
Maximilien Kintz
Erkennung und Bewertung von Zukunftsthesen
Ausgangssituation
Die Firma DER TRENDBEOBACHTER rund um Mathias Haas begleitet Unternehmen hinsichtlich Identifikation von und Beratungen zu relevanten Megatrends. Diese werden bislang durch manuelle Recherche in allgemeinen oder fachspezifischen Quellen zusammengetragen. Der Einsatz von KI-Methoden kann hier unterstützen, eine große Datenbasis automatisiert zu analysieren und hinsichtlich enthaltener Zukunftstrends und Veränderungscluster auszuwerten.
Lösungsidee
Im QuickCheck wurden zwei unterstützende KI-Assistenzfunktionen untersucht: Die Erschließung neuer, unbekannter Trends aus einer großen Zahl aktueller Quellen wie Studien oder Zeitungsartikel, und die Prüfung bzw. Validierung von bereits aufgestellten Thesen anhand dieser Datenbasis.
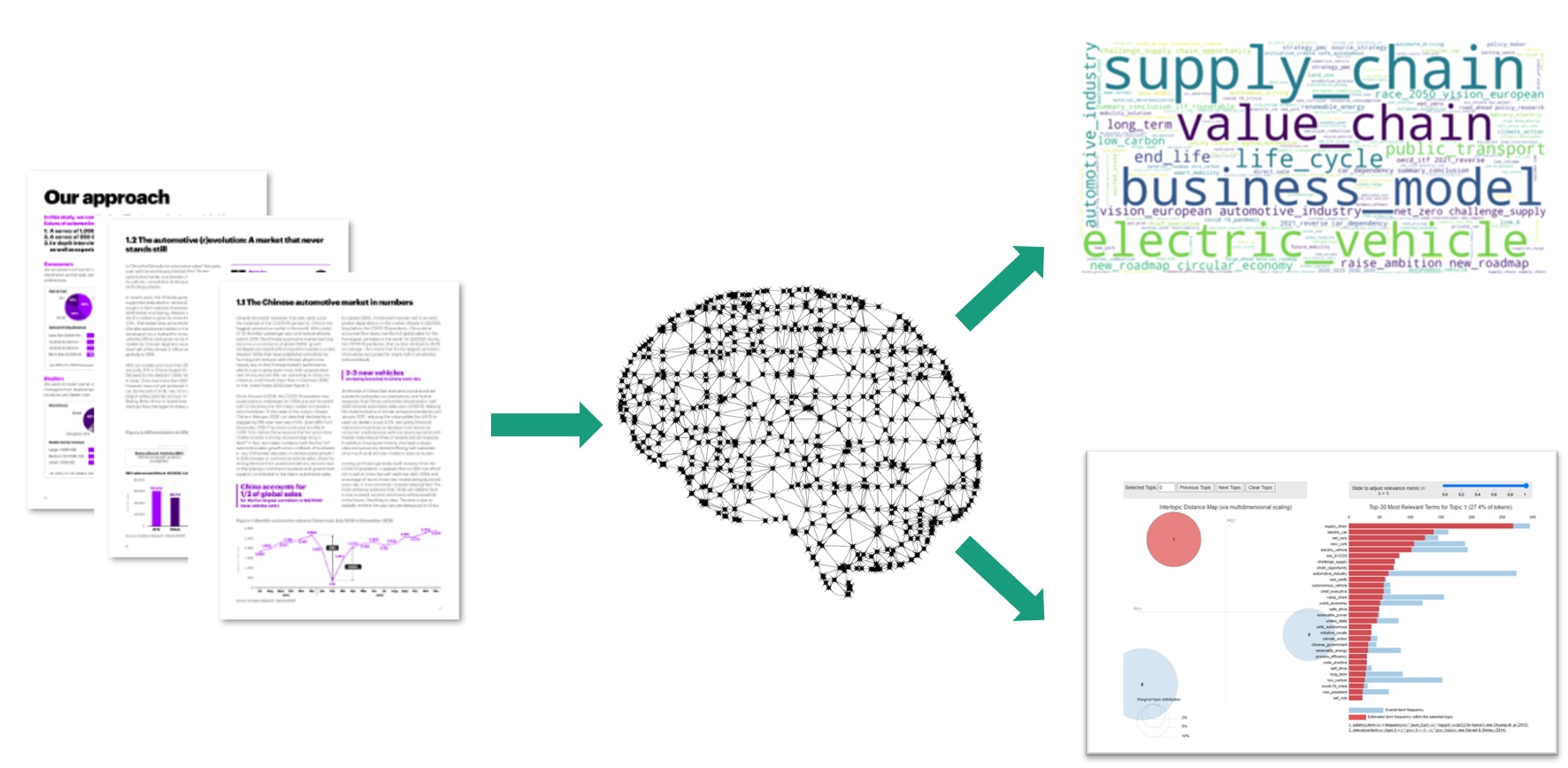
Nutzen
Durch den Einsatz von KI wird es DEM TRENDBEOBACHTER möglich, neue MegaTrends durch automatisierte Analyse großer Datenmengen schneller als andere Beratungsunternehmen zu identifizieren. So findet die KI u.U. auch Themen, die Menschen bislang übersehen haben.
Darüber hinaus kann durch automatisierte Erkennung bzw. Validierung von individuellen, die eigene Firma betreffenden Zukunftstrends generell jedes Unternehmen profitieren, das sich einen Überblick über aktuelle oder sich erst noch anbahnende Entwicklungen in ihrem Umfeld bzw. ihrer Branche verschaffen möchten, um dadurch fit für die Zukunft und somit konkurrenzfähig zu bleiben.
Umsetzung der KI-Applikation
Die im Quickcheck entstandenen prototypischen KI-Funktionen unterstützen folgende Anwendungen:
- Identifizierung von neuen Trends und MegaTrends durch unüberwachtes Clustering von Themen auf einem großen textuellen Datensatz.
- Validierung von aufgestellten Zukunftsthesen anhand semantischer Ähnlichkeitsabgleiche auf dem Datensatz, wodurch Stellungnahmen gefunden werden, die eine These entweder bekräftigen oder widerlegen.