Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«
Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«Quick Check
Ausgangssituation
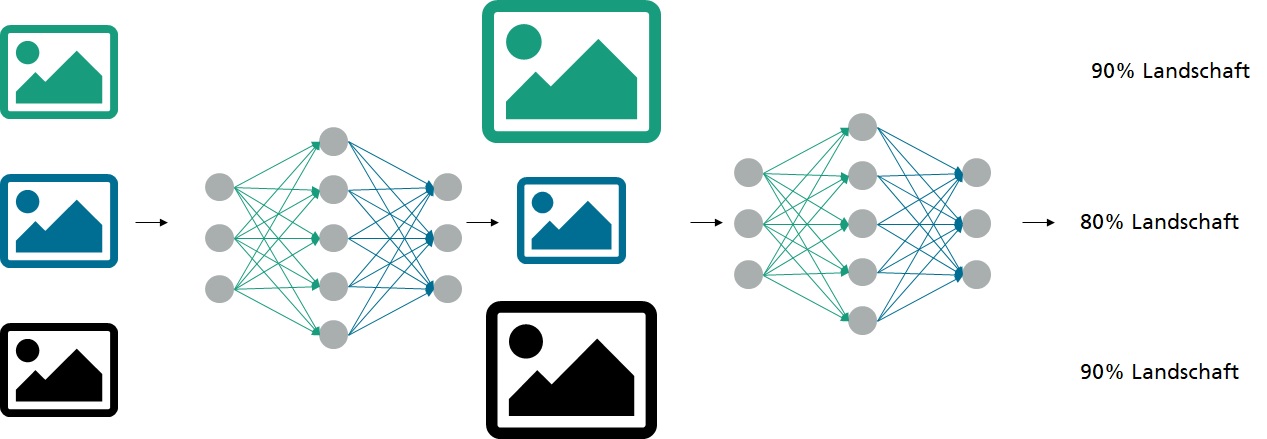
Beim Training von KI-Modellen und insbesondere neuronalen Netzen werden große Mengen von Daten benötigt. Aktuelle Forschungen zeigen, dass nicht alle Trainingsbilder gleich viel wert sind. So haben minderwertige Daten keinen oder sogar einen negativen Einfluss auf KI-Modelle und können ohne Genauigkeitseinbuße entfernt werden, um Kosten zu reduzieren. IDS bietet seinen Kundinnen und Kunden Industriekameras sowie eine Plattform, in der KI-Modelle nach eigenen Anforderungen trainiert werden können. Ziel dieses Projekts ist es, ein Verfahren zu finden, welches minderwertige Daten identifizieren kann und es Anwendern erlaubt, diese frühzeitig aus dem Deep Learning-Prozess zu entfernen.
Lösungsidee
Einige Veröffentlichungen haben das Thema Datenwert in den letzten Jahren aufgegriffen. Durch Reinforcement Learning wird ein neuronales Netz trainiert, die Güte von Bildern und ihrer Annotationen zu bewerten. In den beschriebenen Experimenten waren die Ergebnisse überzeugend. Um das Verfahren auf der Kamera anzuwenden, muss es allerdings ohne Annotationen auskommen. Zu klären bleibt also, ob das Verfahren auf Bilddaten funktioniert und ob es auch ohne Annotationen stabil läuft.