Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«
Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«Quick Check
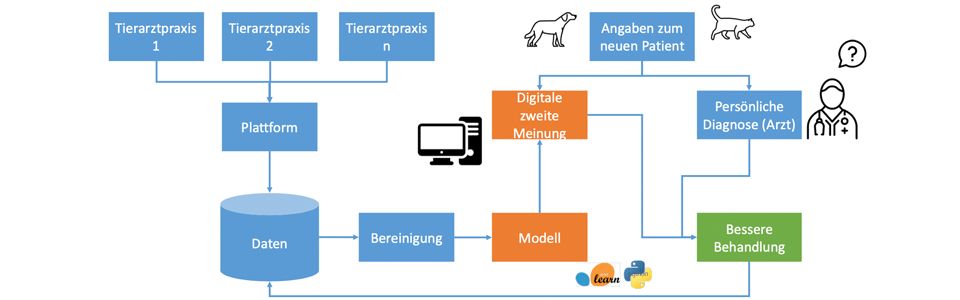
Ausgangssituation
Aus Zeit- oder Kostengründen wird oft auf eine zweite Meinung in der Veterinärmedizin verzichtet. Der Quickcheck-Partner verwaltet eine webbasierte Praxissoftware, die Daten zu behandelten Tieren, deren Behandlungsverläufen, Diagnosen und Infos zur Anamnese erfasst. Ein KI-Modell soll mit diesen Daten trainiert werden, um die Diagnose für die Erkrankung eines Tieres prognostizieren zu können.
Lösungsidee
Die historischen Daten zu den Tierarztbe-suchen, die in der Praxissoftware vorliegen, sollen für das Erstellen eines Machine Learning Algorithmus genutzt werden. Die Algorithmen erkennen Muster und Zusammenhänge, die in der Vergangenheit zu bestimmten Diagnosen führten. Diese Erkenntnisse können in Zukunft in Form ei-ner digitalen zweiten Meinung die fachliche Expertise des Tierarztes ergänzen.