Ausgangssituation
Logistikdienstleister stehen vor der Herausforderung sowohl den Service der Lieferbarkeit zu erfüllen als auch Lagerkosten für Artikel minimal zu halten. Dafür ist die präzise Vorhersage des zukünftigen Bedarfs der im Bestand vorhandenen Artikel essenziell. Zeitfracht GmbH ist ein führendes Logistikunternehmen der Buch- und Medienbranche mit Zulieferungen an bis zu 6500 Buchhändler. Augenblicklich werden die zukünftigen Bedarfe der Artikel aus den historischen Daten der letzten 30 Tage mit einem regelbasierten Verfahren geschätzt und nachträglich manuell durch Experten im Einkauf adjustiert. Das Verfahren kann jedoch den zukünftigen Bedarf nur für gewisse Artikel vorhersagen und weist einen relativ hohen Schätzfehler für einzelne Warengruppen auf.
Lösungsidee
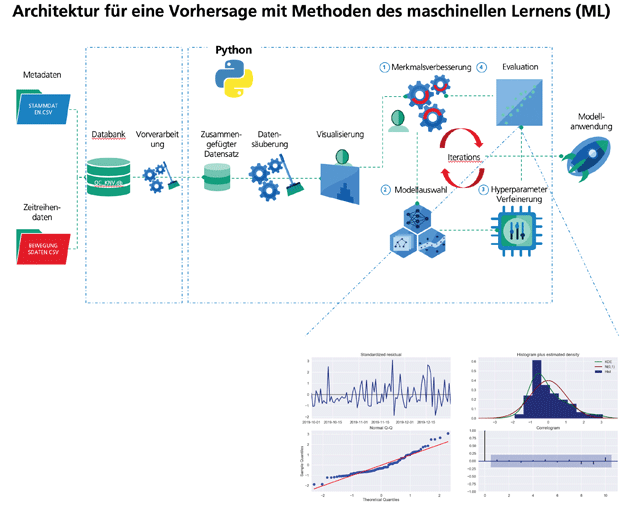
Die Vorhersage des zukünftigen Bedarfs soll nun mittels Methoden des überwachten Maschinellen Lernens verbessert werden. Dafür bedarf es der Aufbereitung der Daten pro Artikel, um eine Vorhersage auf Artikelebene für den nächsten Zeitschritt (Tages- oder Wochenbasis) zu ermöglichen, sowie der Extraktion von aussagekräftigen Informationen in Form von relevanten Merkmalen für die Vorhersage. Dabei sollen Merkmale aus den historischen Daten (Bedarfe der Vergangenheit) extrahiert (u.a. mittels unüberwachter Clusteranalysen) und mit Metadaten der einzelnen Artikel kombiniert werden. Für die Vorhersage können Regressionsverfahren des klassischen Maschinellen Lernens oder tiefe Neuronale Netze verwendet werden.
Nutzen
Die präzise und verbesserte Vorhersage der Bedarfe auf Artikelebene mittels ML-Methoden verbessert die Lieferfähigkeit, reduziert Lager- und Opportunitätskosten in Form von entgangenen Umsätzen sowie Kundenabwanderung und ermöglicht somit einen optimalen Service und Kapitalbindung. Augenblicklich manuell durchgeführte Korrekturen können in Zukunft schrittweise automatisiert werden. Die Vorhersagegenauigkeit kann mit der des aktuell verwendeten Verfahrens verglichen werden, um mögliche Verbesserungen zu quantifizieren.
Umsetzung der KI-Applikation
Für die Vorhersage wurden verschiedene Regressionsmodelle des klassischen Maschinellen Lernens (ARIMA Modelle sowie XGBoosting Trees aus der Familie der Ensemble Lerner) und tiefe Neuronale Netze (rückgekoppelte neuronale Netze mit Long-Short-Term Memory) exploriert. Dabei wurde ein Datensatz mit 600.000 Artikel und historischen Daten über 3 Jahre (2017 – 2020) verwendet. Zu den größten Herausforderungen des Datensatzes gehören Long-Tail-Artikel, Neuerscheinungen und schwer vorhersehbare externe Einflüsse, die die Nachfrage stark beeinflussen, wie z. B. politische, soziale oder mediale Ereignisse. Um den Merkmalsraum für die Vorhersage anzureichern, wurde ein unüberwachte Clusteralgorithmus (Fuzzy C-Means) verwendet, um Artikel mit ähnlichem Absatzverhalten zu gruppieren. Die Clusterzugehörigkeit kann (a) als weiteres informatives Merkmal zur Erfassung von Saisonalität und des Absatzverhaltens im Zeitverlauf und (b) als wichtiger Indikator für das Unternehmen (Entscheidungshilfe für die Sortiment-Auswahl) verwendet werden. Besonders XGBoosting Trees konnten das Nachfrageverhalten einzelner Artikel mit einem geringen Schätzfehler pro Warengruppen vorhersagen und übertrafen dabei die Vorhersagen des bereits implementierten Systems in der Genauigkeit. Die Ergebnisse des Projektes sollen nun im nächsten Schritt für den Einsatz in einer produktiven Umgebung in Kooperation mit Zeitfracht GmbH weiterentwickelt werden.
 Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«
Fraunhofer-Gesellschaft | KI-Fortschrittszentrum »Lernende Systeme und Kognitive Robotik«